Author : Nishana Hafsath KT
Nishana works as a data engineer in Beamlytics. She has created sales forecasting and demand forecasting models as part of our product Beamlytics Lens . Please reach out to Nishana if you want guidance on automating your MLOps pipeline.
Email : Nishana@beamlytics.com
In today’s data-driven world, machine learning models have become the driving force behind uncovering valuable insights and making data-backed decisions. However, as data volumes continue to grow exponentially, managing the entire lifecycle of these models can be a significant challenge. From data preparation and model training to deployment and monitoring, each stage requires careful orchestration and automation to ensure consistent and reliable performance.
This is where Machine Learning Operations (MLOps) comes into play. MLOps offers a set of practices and principles that aim to streamline and automate the deployment and maintenance of machine learning models in production environments. By embracing MLOps, organizations can reduce manual intervention, minimize errors, and accelerate the time-to-market for their data-driven products and services.
At Beamlytics, we heavily rely on Google Cloud’s BigQuery ML capabilities to build and deploy machine learning models on our large-scale data warehouses. However, we encountered difficulties in ensuring our models were consistently trained with the latest data. Manual intervention was required to monitor for new data, retrain models, and redeploy them, leading to inefficiencies, potential inconsistencies, and delays in delivering up-to-date insights to our customers.
To address these challenges and unlock the true potential of our BigQuery ML workflows, we embarked on a journey to implement a robust MLOps pipeline leveraging various Google Cloud services.
This blog post will delve into the details of our step-by-step approach, enabling seamless model training, deployment, and monitoring as new data arrives, while ensuring reproducibility, auditability, and scalability throughout the entire process.

Step 1. Data Preparation and Versioning: Building a Strong FoundationStep 1. Data Preparation and Versioning: Building a Strong Foundation
The foundation of any successful MLOps pipeline lies in proper data preparation and versioning. We utilized tools like BigQuery Data Transfers and Dataflow pipelines to load and preprocess our data into BigQuery tables. To ensure reproducibility and auditability of our models, we implemented data versioning.
- Storage: In our product, we only use BigQuery to store raw and pipeline-processed data. However, if the use case requires data versioning, the option of using Cloud Storage buckets can be employed.
- Clear Naming Conventions: We implemented a clear and consistent naming convention for data versions, including timestamps or version numbers, for easy identification and tracking.
- Metadata Management: Metadata management involves enriching the stored data with comprehensive metadata, such as data source, transformation details, and responsible parties, to enhance understanding and traceability.While we do not currently implement metadata management, it should be considered if the use case demands it.
Step 2. Monitoring for New Data: Triggering Retraining at the Right Time
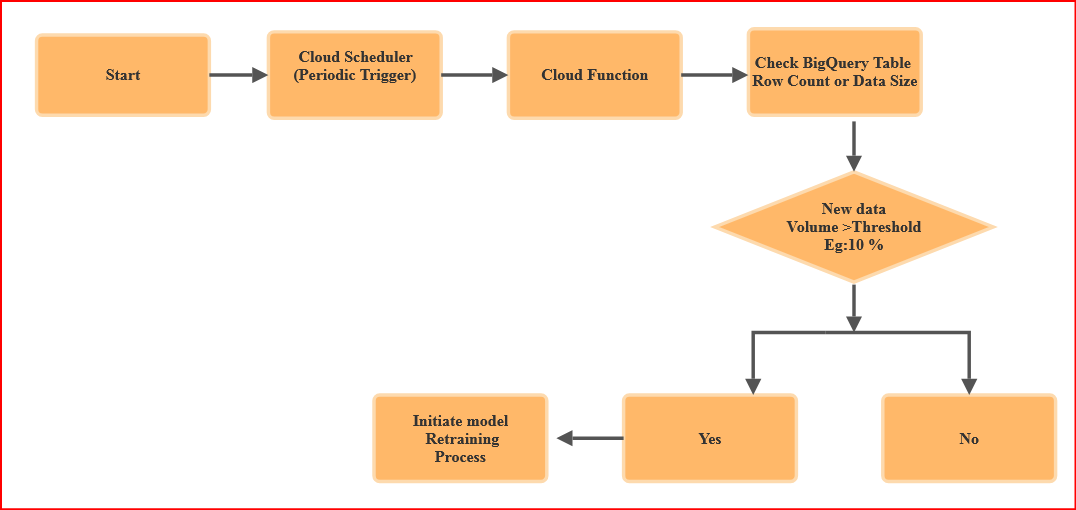
To ensure our models were always trained on the latest data, we needed a mechanism to monitor our BigQuery tables for new data arrivals. We leveraged Cloud Scheduler to trigger a Cloud Function periodically, which checked the row count or data size of the relevant BigQuery tables. If the new data volume crossed a predefined threshold (e.g., 10% of the total rows), the Cloud Function initiated the model retraining process.
Step 3. Model Training and Deployment: Automating the Process
Once the need for retraining was identified, our Cloud Function executed BigQuery ML queries to train a new model on the latest data. We utilized the BigQuery API or SQL queries to create and train the new model, ensuring consistency and reproducibility across different training runs.
After training the model, we exported the trained model artifact to a Cloud Storage bucket for versioning and deployment purposes. This step allowed us to maintain a history of trained models and easily roll back to previous versions if necessary.
To deploy the trained model, we updated an existing Cloud Function with the new model artifact. The Cloud Function loaded the model from Cloud Storage and served online predictions using the updated model.
Step 4. Monitoring and Logging: Ensuring Reliability and Observability
Monitoring and logging are crucial aspects of any production-ready MLOps pipeline. We set up monitoring and alerting for our Cloud Scheduler jobs, Cloud Functions, and BigQuery tables using Cloud Monitoring and Cloud Logging. This allowed us to track the performance and health of our pipeline, identify potential issues, and take corrective actions promptly.
We also implemented comprehensive logging throughout our pipeline, capturing important events, metrics, and debug information. This enabled us to troubleshoot issues efficiently and maintain a detailed audit trail of our MLOps activities.
Step 5. Continuous Integration and Deployment: Streamlining Updates
To streamline updates and ensure consistent deployments, we integrated our MLOps pipeline with Cloud Build, a powerful continuous integration and delivery (CI/CD) platform. Whenever a new model was trained, Cloud Build automatically created containerized deployments of our model serving components (Cloud Functions, Cloud Run services, etc.) and deployed them to the appropriate environments.
This approach allowed us to enforce strict testing and validation processes, ensuring that any updates to our pipeline or model serving components were thoroughly tested before deployment. Additionally, it facilitated easy rollbacks and version management, enabling us to quickly revert to a previous working state if needed.
Step 6. Collaboration and Communication: Fostering Teamwork and Transparency
Effective collaboration and communication are essential for the success of any complex system like an MLOps pipeline. We leveraged various tools and practices to foster teamwork and transparency throughout the development and maintenance of our pipeline.
- Version Control: We utilized GitHub for version control of our pipeline code, Cloud Functions, BigQuery ML models, queues, data cleanup pipelines or queries, and other related components. This enabled collaboration, code reviews, and traceability of changes across the entire system.
- Collaboration Channels: We established dedicated communication channels (e.g., Google Chat) for discussing pipeline-related issues, sharing updates, and facilitating cross-functional collaboration.
Instead of using complex documentation tools, we opted for simpler solutions like Google Sheets, Docs, and Presentations to maintain documentation for our pipeline components, processes, and best practices, ensuring accessibility for all team members.
The Benefits of an Automated MLOps Pipeline
By implementing this automated MLOps pipeline for our BigQuery ML workflows, we achieved significant benefits:
- Consistent Model Updates: Our BigQuery ML models are consistently retrained with the latest data, ensuring accurate and up-to-date predictions, leading to more reliable decision-making.
- Increased Efficiency: Manual intervention for monitoring, retraining, and deployment is eliminated, freeing up valuable time and resources for our data science team.
- Reproducibility and Auditability: Data versioning and logging mechanisms enable us to easily track and reproduce our model training processes, ensuring compliance and facilitating model improvement over time.
- Scalability: The pipeline can be easily adapted and replicated for other BigQuery ML projects within our organization, promoting consistency and efficiency across our machine learning efforts.
Conclusion
Implementing a robust MLOps pipeline for our BigQuery ML workflows has been a game-changer for Beamlytics. By automating the model training, deployment, and monitoring processes, we have significantly reduced manual effort, minimized errors, and accelerated the delivery of up-to-date insights to our customers.
Furthermore, the versioning, monitoring, and collaboration practices we’ve implemented have enhanced the reproducibility, auditability, and scalability of our machine learning models, enabling us to iterate and improve them with confidence.
As we continue to expand our data-driven offerings, our MLOps pipeline will serve as a solid foundation, enabling us to streamline the deployment and maintenance of machine learning models across various domains and use cases.
We encourage other organizations leveraging BigQuery ML to embrace MLOps principles and practices, as they can unlock significant operational efficiencies and empower teams to focus on higher-value tasks, such as model experimentation and optimization, ultimately driving greater business value from their machine learning initiatives.
Get in touch if you need more information




